Escape From Tarkov Craft Profit Counter
About
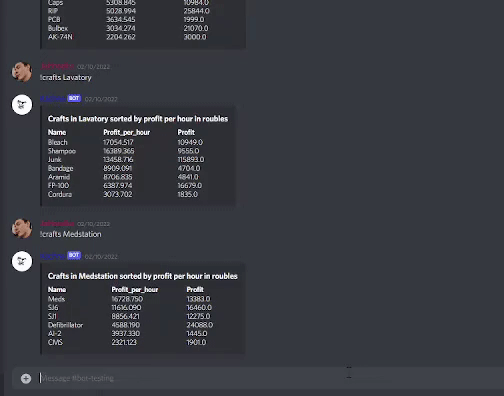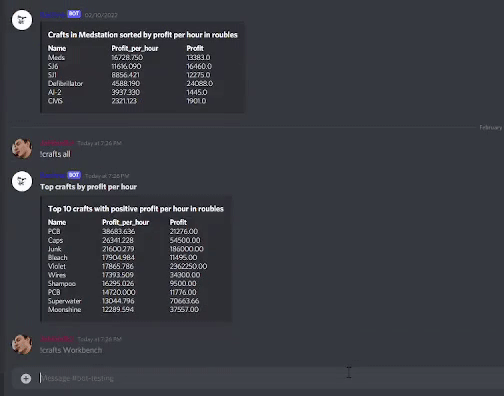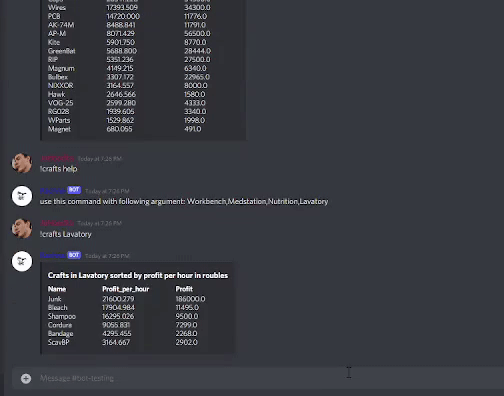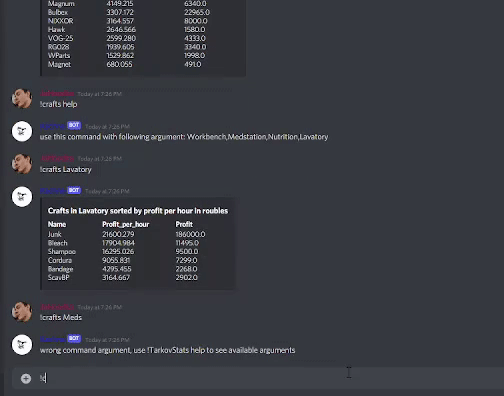
Pipeline in this example is inspired by game Escape from Tarkov. It is a realistic FPS game. Beside shooting enemies, Players can earn and sell items in a game market which is driven by players themselves. The price of each item is changing in real-time based on Demand-supply mechanics. Another important game mechanic is that players can create the items themself in their specific stations. Items created and required for each crafts can be bought on the market, so players can earn in-game money by producing the items. Because price of each item is not stable, some crafts are more profitable than others. My idea was to take data from an API source that gives information of all available crafts players can do together with price of each item. I will use this data to sort and analyze the data and output them in form that might help players know which crafts is more profitable and suitable.
In this example I will show you a process of creating pipeline with a bit more complicated use. You will learn about creating a source that enables us to use query in our API requests.
Source
First we have to create our source to pump the data to the pipeline. We will be using aiohttp library for our custom source. We will start by creating our source class. As you can see in the code below.
class IOHTTPSource(bspump.TriggerSource):
def __init__(self, app, pipeline, choice=None, id=None, config=None):
super().__init__(app, pipeline, id=id, config=config)
async def cycle(self):
async with aiohttp.ClientSession() as session:
async with session.post('https://tarkov-tools.com/graphql', json={'query': query}) as response:
if response.status == 200:
event = await response.json()
else:
raise Exception("Query failed to run by returning code of {}. {}".format(response.status, query))
await self.process(event)
As you can see in the cycle method. We are using asynchronous functions for the API requests. As you can see in the code I am creating Session which is used in aiohttp for more information check AIOHTTP Documentation. I am using post method with a query parameter as seen below.
query = """
query {
crafts {
source
duration
rewardItems {
quantity
item {
shortName
lastLowPrice
}
}
requiredItems {
quantity
item {
shortName
lastLowPrice
}
}
}
}
"""
I created this query using playground interface made by the API authors. Here is the link if you would like to use this API.
Now you can try to copy-paste the code below and try it for yourself.
#!/usr/bin/env python3
import aiohttp
import bspump
import bspump.common
import bspump.http
import bspump.trigger
import pandas as pd
import bspump.file
query = """
query {
crafts {
source
duration
rewardItems {
quantity
item {
shortName
lastLowPrice
}
}
requiredItems {
quantity
item {
shortName
lastLowPrice
}
}
}
}
"""
class IOHTTPSource(bspump.TriggerSource):
def __init__(self, app, pipeline, choice=None, id=None, config=None):
super().__init__(app, pipeline, id=id, config=config)
async def cycle(self):
async with aiohttp.ClientSession() as session:
async with session.post('https://tarkov-tools.com/graphql', json={'query': query}) as response:
if response.status == 200:
event = await response.json()
else:
raise Exception("Query failed to run by returning code of {}. {}".format(response.status, query))
await self.process(event)
class SamplePipeline(bspump.Pipeline):
def __init__(self, app, pipeline_id):
super().__init__(app, pipeline_id)
self.build(
IOHTTPSource(app, self).on(bspump.trigger.PeriodicTrigger(app, 5)),
bspump.common.PPrintProcessor(app,self),
bspump.common.NullSink(app, self),
)
If everything works correctly, you should be getting similar output.
'source': 'Workbench level 3'},
{'duration': 60000,
'requiredItems': [{'item': {'lastLowPrice': 39000,
'shortName': 'Eagle'},
'quantity': 2},
{'item': {'lastLowPrice': 15000,
'shortName': 'Kite'},
'quantity': 2}],
'rewardItems': [{'item': {'lastLowPrice': None,
'shortName': 'BP'},
'quantity': 120}],
'source': 'Workbench level 3'},
{'duration': 61270,
'requiredItems': [{'item': {'lastLowPrice': 15000,
'shortName': 'Kite'},
'quantity': 2},
{'item': {'lastLowPrice': 39000,
'shortName': 'Eagle'},
'quantity': 2},
{'item': {'lastLowPrice': 31111,
'shortName': 'Hawk'},
'quantity': 2}],
'rewardItems': [{'item': {'lastLowPrice': None,
'shortName': 'PPBS'},
'quantity': 150}],
.
.
.
There are probably hundreds of JSON lines in your console right now. It is not a nice way to output your data right? Let’s implement our filter processor then.
Filter Processor
This filter processor is used for very specific use-case in this example. The goal as you can remember was to filter incoming data. The goal is to create a dataframe that contains data where each row has information about station in which the craft is created, duration of the craft ,price of items needed to perform the craft, name and price of item/s that we obtain by the craft, profit of the craft, and profit per hour. As you can see there is a lot of indexes we have to create.
class FilterByStation(bspump.Processor):
def __init__(self, app, pipeline, id=None, config=None):
super().__init__(app, pipeline, id=None, config=None)
def process(self, context, event):
my_columns = ['station', 'name', 'output_price_item', 'duration', 'input_price_item', 'profit', 'profit_per_hour']
df = pd.DataFrame(columns=my_columns)
for item in event["data"]["crafts"]:
duration = round((item["duration"])/60/60, ndigits=3)
reward = item["rewardItems"][0]
name_output = reward["item"]["shortName"]
quantity = reward["quantity"]
output_item_price = reward["item"]["lastLowPrice"]
if output_item_price is None: # checks for NULL values
output_item_price = 0
output_price_item = quantity * int(output_item_price)
station_name = item["source"]
profit = 0
profit_p_hour = 0
input_price_item = 0
for item2 in range(len(item["requiredItems"])):
required_item = item["requiredItems"][item2]
quantity_i = required_item["quantity"]
input_item = required_item["item"]["lastLowPrice"]
if input_item is None:
input_item = 0
price_of_input_item = input_item * quantity_i
input_price_item = input_price_item + price_of_input_item
profit = output_price_item - input_price_item
profit_p_hour = round(profit / duration, ndigits=3)
df = df.append(
pd.Series([station_name,
name_output,
output_price_item,
duration,
input_price_item,
profit,
profit_p_hour],
index=my_columns), ignore_index=True)
event = df
return event
You can copy-paste the code above and everything should work just fine. Don’t forget to reference the processor in the self.build() method.
class SamplePipeline(bspump.Pipeline):
def __init__(self, app, pipeline_id):
super().__init__(app, pipeline_id)
self.build(
IOHTTPSource(app, self).on(bspump.trigger.PeriodicTrigger(app, 5)),
FilterByStation(app, self),
bspump.common.PPrintProcessor(app, self),
bspump.common.NullSink(app, self),
)
If you want more detail of what it does. It firstly goes through the whole json, then it gets data for each of the index if possible (otherwise zero is used instead of null), and appends the record as a row in our dataframe. I am using Pandas in this example. If you are not familiar with Pandas make sure you checked their Documentation
Now output in your console should like like this:
station name output_price_item duration input_price_item profit profit_per_hour
0 Booze generator level 1 Moonshine 286999 3.056 236998 50001 16361.584
1 Intelligence Center level 2 Flash drive 180000 34.222 151498 28502 832.856
2 Intelligence Center level 2 Virtex 88000 37.611 210993 -122993 -3270.134
3 Intelligence Center level 2 SG-C10 130000 38.889 206978 -76978 -1979.429
4 Intelligence Center level 2 RFIDR 215000 53.333 40000 175000 3281.271
.. ... ... ... ... ... ... ...
128 Workbench level 3 PBP 0 11.972 265888 -265888 -22209.155
129 Workbench level 3 M995 0 15.994 211000 -211000 -13192.447
130 Workbench level 3 M61 0 16.644 233331 -233331 -14018.926
131 Workbench level 3 BP 0 16.667 108000 -108000 -6479.870
132 Workbench level 3 PPBS 0 17.019 170222 -170222 -10001.880
[133 rows x 7 columns]
We can agree that this looks much more better than raw JSON, but this is not the end we still need to send the data somewhere for out bot
Dataframe to csv Processor
To make the data available for our Discord bot, we will save them to a directory as a csv file. This processor is really simple as we call only one function from the Pandas library.
You can copy paste the code of the processor
class DataFrameToCSV(bspump.Processor):
def __init__(self, app, pipeline, id=None, config=None):
super().__init__(app, pipeline, id=None, config=None)
def process(self, context, event):
event.to_csv('./Data/TarkovData.csv', index=False)
return event
Once again dont forget to include the processor in our self.build() method.
class SamplePipeline(bspump.Pipeline):
def __init__(self, app, pipeline_id):
super().__init__(app, pipeline_id)
self.build(
IOHTTPSource(app, self).on(bspump.trigger.PeriodicTrigger(app, 5)),
FilterByStation(app, self),
bspump.common.PPrintProcessor(app, self),
DataFrameToCSV(app, self),
bspump.common.NullSink(app, self),
)
This wont change our output in console, but it should create a csv file in your current directory.
What next
Now we have a function pipeline. You can do anything with the output data. For example, I created a simple discord bot that sends a message with the updated data you can try to make your own discord bot using this tutorial: Getting Started with Discord Bots.